



Identity Orchestrator
Your identity spine. Under your roof.
Identity Orchestrator builds and manages an owned identity graph inside your cloud. Resolve people and households across any ID — without moving or duplicating a single row of data.
Fragmented identity is a losing battle
Every source names the same person differently, and the cost of reconciling them compounds across every campaign, every analysis, every activation.
Identity sprawl
CRM, digital, third-party — the same person lives under a dozen different IDs
Vendor lock-in
Your identity spine shouldn’t live inside someone else’s black box
Lost reach
Broken matches shrink audiences and flatten performance at every step
What happens when identity belongs to you
Here’s what it looks like when your identity graph works for you instead of against you.
Unified view
Resolution, across every ID and every channel
No data movement
The graph runs where your data already lives
Bigger audiences
Probabilistic and deterministic matching extends reach without sacrificing precision
True portability
Take your graph anywhere — no rebuild, no re-ingest, no vendor handshake
Own the graph. Own the outcome.
Ready for deployment inside your cloud, with every rule, every algorithm, and every ID under your control
THE SOLUTION
Your spine stops being someone else's product
Identity Orchestrator runs inside your cloud, under your governance, with your keys, so the graph your business depends on stays in your control.
THE SOLUTION
Tune the logic without rebuilding the graph
Match rules, edge thresholds, and resolution windows configure per use case. Adjust them when the business changes, and the graph adapts without a re-platforming project.
THE SOLUTION
Resolve any ID, today or tomorrow
Email, phone, MAID, cookie, pseudonymous — the graph treats every identifier as input and adapts as the identifier landscape changes underneath it.
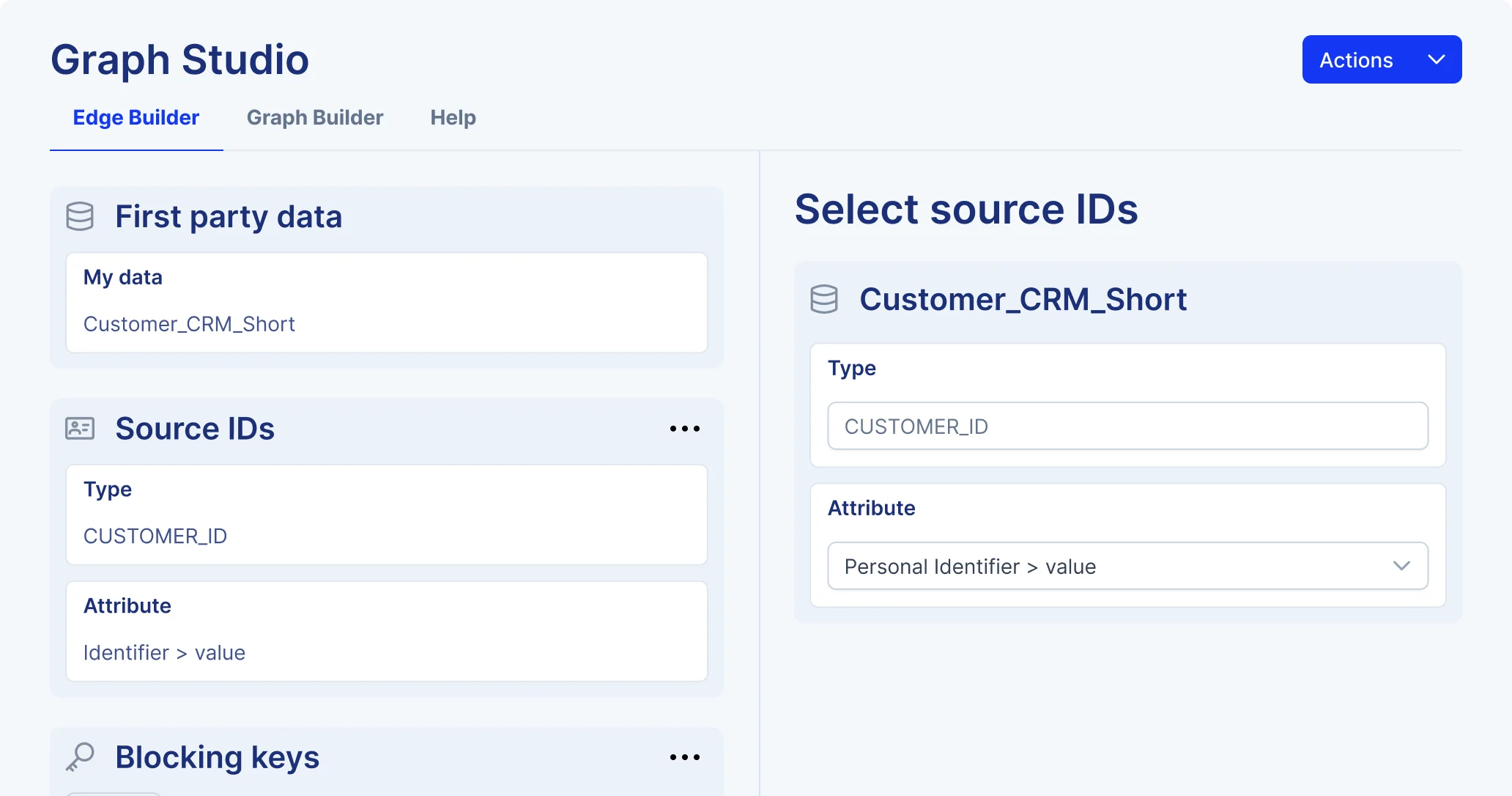
How it works
An identity graph, without the identity-graph project
Identity Orchestrator deploys inside your cloud and resolves identities on your data in place, using rules you configure, algorithms you tune, and IDs you define in your cloud. Scale up without moving data, standing up new pipelines, or handing the keys to a third party.
Customizable rules and heuristics
Configure matching logic around your business rules, not someone else’s defaults.
Probabilistic + deterministic matching
Combine exact-match precision with machine-learned inference to expand reach without losing rigor.
ID agnostic
Resolve across email, phone, MAIDs, cookies, pseudonymous IDs, and whatever comes next.
Seamless graph enrichment
A Marketplace of data normalized and ready to instantly augment your ability to match people in the graph, increase addressability, and add new attributes.
One graph. Zero handoffs.
Put resolved identity to work under a single governance layer.
For analysts
Analyze the customer, not the ID.
Run attribution, cohort analysis, and lifetime value on unified people instead of reconciling ten different IDs for every query. Every number rolls up to someone you can actually find again.

For marketers
Reach the right person, not their fragments.
Build audiences against the full picture of your customer — resolved across devices, channels, and partners — and take the same audience wherever you activate. The person stays whole even when the channels aren’t.

For engineers
A graph that deploys where your data lives.
Identity Orchestrator runs inside your cloud, integrates with your existing warehouse, and resolves at query time. No new pipelines, no data replication, no new on-call rotation.
i want to
Identity Truths: The Principles Behind Modern Identity Resolution
Your identity graph belongs in your cloud.
Hosted identity graphs make you a tenant in someone else’s infrastructure — and a line item in someone else’s pricing model. With Narrative Anywhere, Identity Orchestrator runs where your data already runs, under your governance, your controls, your keys. Your spine, your call.
Matching logic isn’t one-size-fits-all.
The right way to resolve a retail customer is not the right way to resolve a B2B buyer or a household viewer. Off-the-shelf graphs force your business into their assumptions. Identity Orchestrator lets you configure the rules, tune the algorithms, and change your mind when the business changes.

ID agnosticism is a feature, not a future.
Cookies fade, MAIDs fragment, pseudonymous IDs multiply. An identity system built for any one of them is obsolete by design. Identity Orchestrator treats every ID as input and resolves across all of them — today and the day after tomorrow.
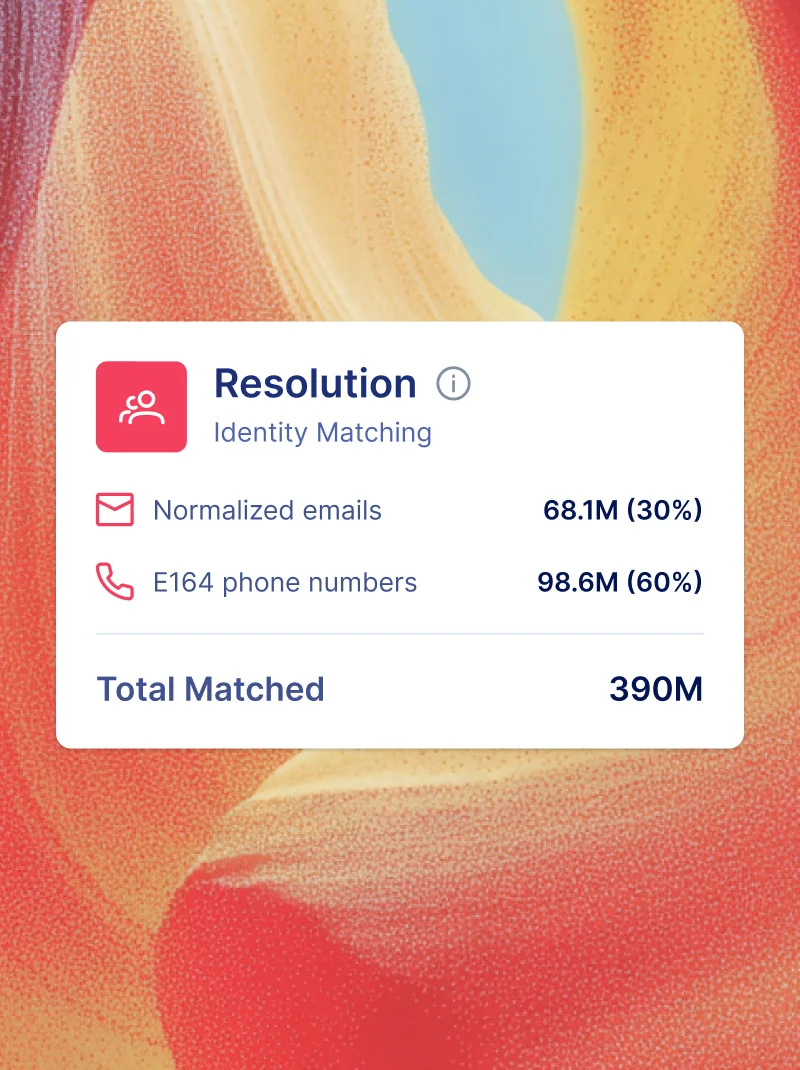
Proven results
Scalable reach without compromise
8+
identifier types supported
2
matching modes in one graph
100%
of data stays in the customer cloud
Proven Results
Reach without compromise
“Partnering with Narrative.io has empowered us to seamlessly scale our offerings across diverse social platforms. Ultimately, this collaboration has been key to achieving our objective: engaging with our customers exactly where they are."
Dennis O'Donnell, Head of Ad Product
The Weather Company

“What I am looking for is a #RosettaStone. I don’t have the resources to pick through endless data sets and clean and harmonize them. I am calling it the great marketing emergency. We’ve got all this data, but we need #AI to stitch it together as a means to help our clients drive growth. We have the ability to have a fluid conversation with the consumer at the different points in their journey.”
Domenic Venuto, Chief Product & Data Officer
Horizon

“Traditional commerce media models often expose brands to unnecessary privacy risks by moving data into third-party environments. Our work with Narrative eliminates that risk while unlocking sophisticated audience-building capabilities that deliver real outcomes.”
Marni Schpario
Block

Ask Us Anything
Straight answers to real customer questions.
Most teams are normalizing live data within days of connecting their first sources — not months. There's no multi-quarter implementation, no professional services dependency, no bespoke build required. You connect your sources, define what coherence looks like for your use case, and Narrative does the translation work. The timeline question is usually less about setup and more about how quickly your team can act on data that's finally consistent.
Those tools move data and act on it. They don't normalize it. They're built on the assumption that the data arriving is already clean, consistent, and semantically coherent — and in most real-world data partnerships, it isn't. Narrative is the layer that makes your existing collaboration and activation infrastructure work the way it was designed to. The teams getting the most from their data stack are typically the ones who've solved normalization first.
Most teams do, at first. The problem isn't the initial build — it's everything after. Every partner schema change breaks it. Every new data source requires rebuilding it. Every team transition means relearning it. The engineering debt compounds faster than the business value accrues. Narrative replaces a perpetual maintenance burden with infrastructure that's designed to absorb that complexity so your team doesn't have to.
Data and analytics teams at companies where external data is a core business input — not a supplement. Typically organizations that are buying data at scale, monetizing their own data assets, or running structured data partnerships with other companies. If your team is spending meaningful engineering time just making external data usable, that's the problem Narrative is built to eliminate.
AI models don't tolerate inconsistency. When a "user" in one dataset isn't recognized as the same "user" in another — different schemas, different taxonomies, different identifiers — your models train on noise and your outputs reflect it. Narrative normalizes data at the source so the AI layer above it is working with signal. Garbage in, garbage out isn't an AI problem. It's a normalization problem.
Your warehouse stores data. Your CDP activates it. Narrative normalizes it — resolving the semantic inconsistencies that make data from different sources incompatible before it ever reaches those tools. We don't replace your stack. We fix the layer underneath it that your stack assumes is already solved.